EM Algorithm and Maximum Likelihood
In this post first we talk about the importance of maximum likelihood and then we evaluate the Expectation Maximization (EM) algorithm.
Maximum Likelihood Interpretation:
Suppose that we have a dataset of i.i.d samples in which is the number of datapoints. We are assuming each datapoint was independently sampled from and we want to estimate . Since these samples are i.i.d we can factorize their joint probability:
Maximum likelihood method looks for the parameter that maximizes this joint probability (or the log of joint probability):
Now suppose that is the set of unique datapoints and , so we can rewrite the equation for :
In this equation is the frequency of each datapoint which shows the emprical distribution of unique datapoints, so by defining as our emprical distribution:
The last equation shows that by using maximum likelihood we are minimizing the KL-divergence between emprical distribution () and the predefined model ().
Expectation Maximization:
Sometimes it’s not easy to find directly, but adding a latent variable to the model makes the joint probability of easier to deal with. In this part we see how we can find an iterative algorithm to improve approximated parameters in each step. We know that for a concave function if and we have Jensen’s inequality.
Image below depicts this inequality for a simple case that we have just two points ():
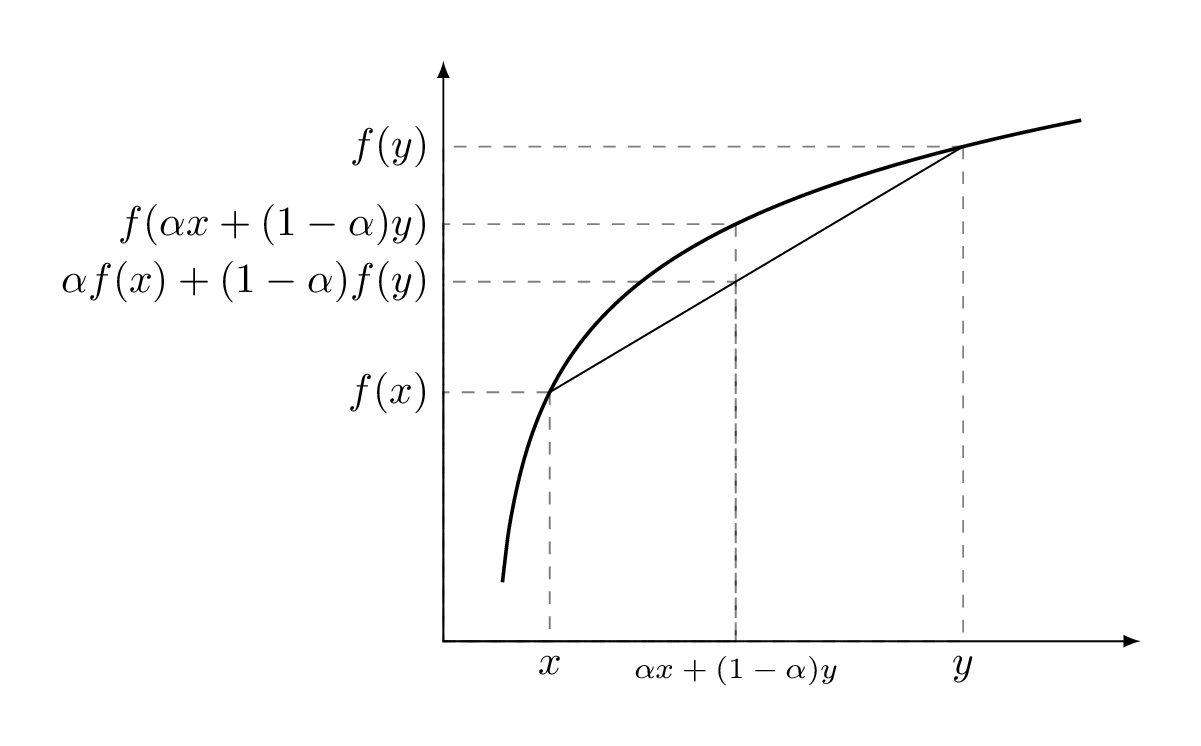
In statistics a special case of Jensen’s inequality holds for the expected value of a concave function.
Now suppose that is the set of all datapoints and in iteration the estimate for is . We want to maximize :
Since we want to make sure that in each iteration our likelihood is getting better (, our best action would be finding the parameter that maximizes the distance between and :
We know that function is concave and adding a sum inside the would provide this opportunity to use Jensen’s inequality. The numerator of the fraction inside log is a marginal probability that can be written as summation of joint probability:
And we have:
Now we see that is playing the role of and since the summation is over , we should add a probability distribution of (something like ) to be able to use Jensen’s inequality. Our different options are:
1- Our first option is :
So we have found a lower bound for and by maximizing this lower bound in each iteration we want to make sure that liklihood is getting better and better:
But is supposed to include all the parameters needed for the joint probability of and which is and in general case is just using a subset of parameters defined in and some other parameters such as parameters needed for may not be updated. So we can evaluate another option.
2- The second option is that uses all the parameters defined in :
And this last equation is the general form of EM algorithm:
E-step:
Compute the expected value of joint probability:
M-step:
Maximize with respect to :