Variational Inference
In probabilistic machine learning we are always assuming that our observations are samples generated from probability distributions and we are dealing with their joint probability:
For each particular problem (or dataset) we can define our model for this joint probability. when the notation used for the probability distribution has semicolon (i.e. ), it means that in our predefined model we have a deterministic but unknwon parameter and we are looking for an estimator (a function of samples) to approximate this parameter :
For example in language modeling we can assume words in a sentence are i.i.d data samples (the sentence is an array of these words ) and our aim is to find the parameters of their distribution:
We can improve this model by adding latent variables. In language modeling we know that sentences are generated by grammar rules, so this prior information can help us to make more accurate models. In other words, in this new model first there are samples generated from hidden variables () and then our observations () are generated by them.
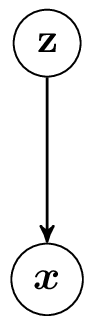
After introducing the latent variables to our model instead of the joint probability of datasamples we should define the joint probability of data and the hidden variables in .
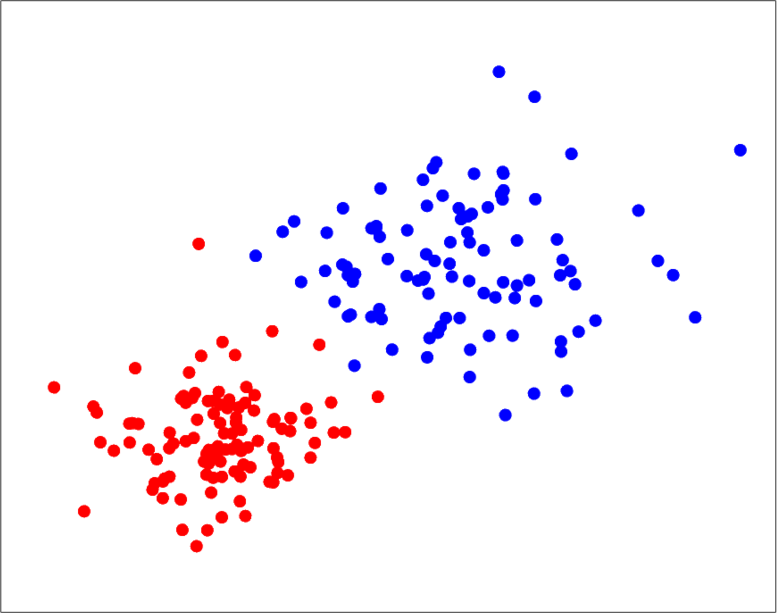
A good example for adding latent variables is clustering. Suppose that first we just see the raw datapoints:

After observing the data we can decide to have two clusters in our model and simply define and similarly . Also we should define the prior information for . (We sometimes assume that the prior for lacks any unknown parameter such as ). So in this clustering example our model for the conditional probability is Gaussian and the parameters for them are .
Now since is not deterministic and it was defined to be a random variable, after observing the data we want to infer and we call it the posterior. By using Bayes rule we can define this distribution based on the model we defined:
Also we know that in continuous case:
Since this integral is over all possible values for if the dimension of is high or the number of different possible values it can take is infinite then is intractable. Now one of the solutions would be estimating by defining a tractable distribution ( a simple distribution that we define ourselves) such as and minimizing the divergence between and :
We have used the equation:
Finally we can write:
We should note than the set of are the parameters we want to estimate . As we see the evidence is just a function of so minimizing with respect to is equal to maximizing the ELBO with respect to this parameter. Also maximizing the ELBO with respect to is equal to maximizing the likelihood. So instead of dealing with which is intractable, we use the ELBO as our objective function.
Why did we start with ?
In variational inference we are approximating an intractable distribution with a tractable one and we want to minimize their divergence (which is different from distance). KL divergence has some important properties:
1-
2- if and only if
So based on these two conditions we see that both and could be our objective functions to make and as similar as possible but the problem with is the intractable part:
We should look for a way to separate tractable and intractable parts from and since both and include , it’s not possible to derive tractable parts from the integral but as we showed in the intractable part () is just inside the function which leads to ELBO.
What does ELBO mean?
By looking at the formula derived for the ELBO, we see:
The ELBO shows that when we are approximating the posterior with , first we have some prior information about and it makes sense to minimize . Also we have observed the data samples which we want to reconstruct and make them as probable as possible. So we should maximize . In other words, before observing the data we had some information and now after observing them we have further information about the model and our approximation for the posterior should make a balance between them.